Kubernetes Storage 101: 浅析 CSI Driver 实践中的挑战与解决方案
Table of Contents

在上一篇文章 《Kubernetes Storage 101: 浅谈如何实现一个 CSI 插件》 中,我们一起探讨了 Kubernetes Container Storage Interface 的基础理论以及插件实现的关键步骤。正如文章末尾所承诺的,本文将继续分享在实际工作环境中应用 CSI 驱动时所面临的挑战,以及针对这些问题的实用解决策略。
时光飞逝,2023 年只剩二周了,这么一想,就很突然。。。
我吧,好像有点拖延症,转眼已经来到年末,也是时候为这个话题画上一个圆满的句号了。
从挂载点说起#
在使用 FUSE 类型的 CSI Driver 时,你是否曾遇到过以下这个熟悉的错误场景,即在访问业务容器中的 mountpoint 时发生错误?
root@csi-s3-example:/# cd /data
bash: cd: /data: Transport endpoint is not connected
我的业务 Pod 运行正常,没有任何异常,那么这个错误是怎么发生的呢?
CSI 工作原理简述#
我们先简单来回顾一下 CSI 的工作原理,以 k8s-csi-s3 为例:
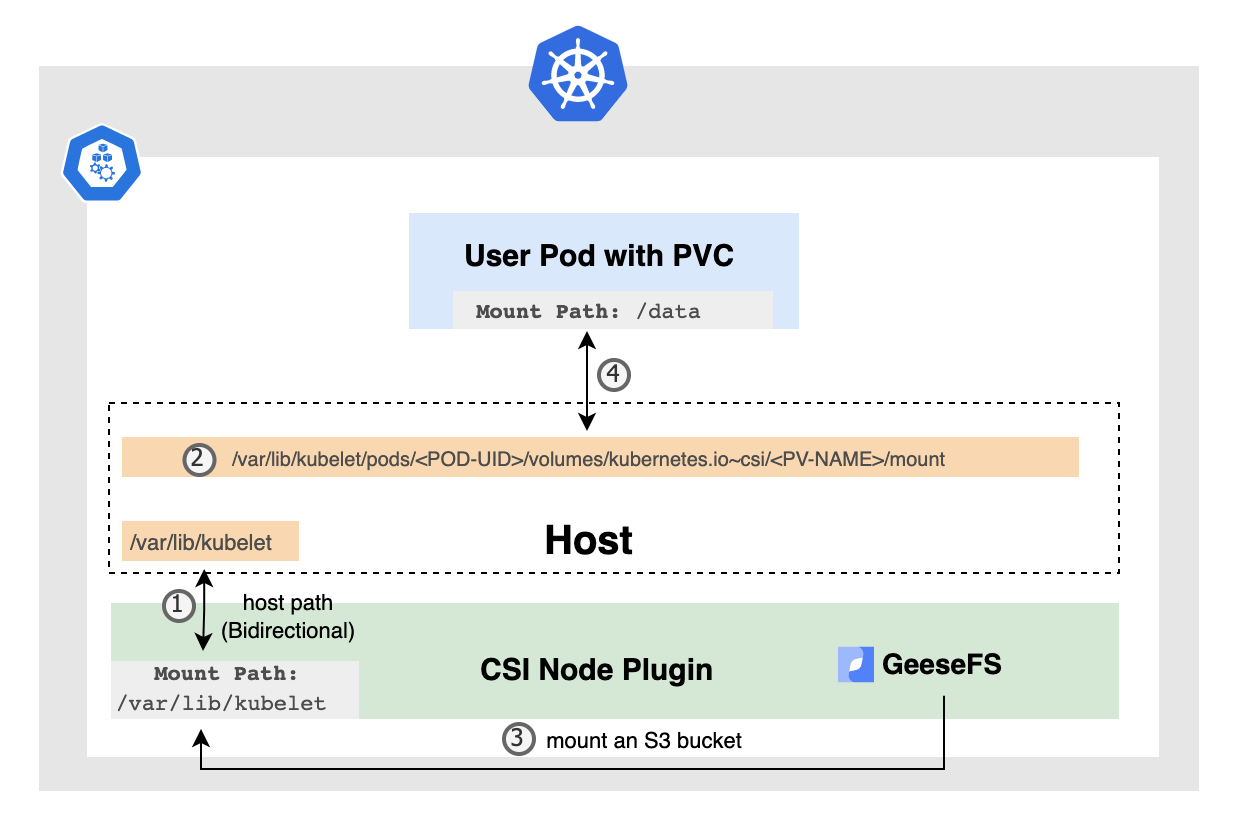
步骤 1: 在部署 CSI Node Plugin 的过程中,我们通常会将宿主机上的 /var/lib/kubelet 目录挂载到驱动程序的容器内,并且需将 Mount Propagation 设置为 Bidirectional。这确保了驱动程序容器内的任何 Mount/Umount 操作能够传播到宿主机上。
步骤 2: 当创建一个带有 PVC 的 Pod 时,一旦 Pod 被调度到某个节点,kubelet 就会负责为这个 Pod 创建它的 Volume 目录。通常,kubelet 为 Volume 创建的目录位于宿主机上的以下路径:/var/lib/kubelet/pods/<POD-UID>/volumes/kubernetes.io~csi/<PV-NAME>/mount。
步骤 3: 与此同时,CSI 驱动程序将在其容器内完成基于进程的挂载操作,geesefs 客户端运行在 CSI Node Plugin 容器中,将 bucket 挂载到上述目录中。
步骤 4: 最后,kubelet 负责将这个为 PVC 创建的目录挂载到业务 Pod 中。
好比说,如果在 Pod 的定义中,我们为一个容器指定了一个挂载点 /data 并关联了一个名为 my-pvc 的 PVC,kubelet 就会将 /var/lib/kubelet/pods/<POD-UID>/volumes/kubernetes.io~csi/<PV-NAME>/mount 目录挂载到容器的 /data 目录。这样,容器内的应用程序就可以通过访问 /data 路径来与存储卷交互,实现数据的读写了。
问题原因分析#
遇到上述错误的原因通常是:CSI Node Plugin 被重启,可能是因为资源限制或其他人为的误操作。这种重启会导致该 Pod 内的 FUSE 进程全部被 Kill 掉,进而导致原有挂载点失效,影响到了业务容器的挂载点。
因为 CSI Driver 和 CO(容器编排器)在完成一次调度过程后不会重新执行 NodePublishVolume 的流程,因此 CO 的流程不会再次被触发,挂载点自然不会自动恢复了。
事实上,这个问题的爆炸半径非常大,它会影响到该 CSI Driver Node Pod 所在节点的所有业务 Pod,非常之恐怖。

面对如此广泛的影响,我们自然要探索有效的解决方案来应对这一挑战。让我们看看如何解决这一问题。
解决方案探讨#
如果我们没有对 CSI Driver 进行特殊的定制,那么解决这个问题的唯一方法可能就是手动重启所有使用了 PVC 的业务 Pod 了。
但是,这种行为对于我们的客户而言,通常是无法接受的,它会导致 Pod 出现短暂的停机时间,凭什么???
恢复挂载点#
我们进入到 CSI Node Plugin Pod,首先能够确认的是 Pod 里的挂载点确实失效了
/var/lib/kubelet/pods # mount|grep bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6
pvc-b03e3152-5f24-4361-9492-f29f662ae694 on /var/lib/kubelet/pods/bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6/volumes/kubernetes.io~csi/pvc-b03e3152-5f24-4361-9492-f29f662ae694/mount type fuse.geesefs (rw,nosuid,nodev,relatime,user_id=65534,group_id=0,default_permissions,allow_other)
/var/lib/kubelet/pods # ls /var/lib/kubelet/pods/bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6/volumes/kubernetes.io~csi/pvc-b03e3152-5f24-4361-9492-f29f662ae694/mount
ls: /var/lib/kubelet/pods/bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6/volumes/kubernetes.io~csi/pvc-b03e3152-5f24-4361-9492-f29f662ae694/mount: Socket not connected
既然已经知道问题的根本原因是出在最初的挂载点身上,那么我们有没其他办法做恢复呢?
#1. 手动卸载
我们的 CSI Node Plugin 是被异常重启的,对于原来的挂载点来说,并没有机会去执行 NodeUnpublishVolume 的操作,所以我们首先是需要做 Umount 的动作。
/var/lib/kubelet/pods # umount /var/lib/kubelet/pods/bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6/volumes/kubernetes.io~csi/pvc-b03e3152-5f24-4361-9492-f29f662ae694/mount
#2. 手动挂载
假设我已经准备好了挂载的所有信息,通过 geesefs 进行挂载。
/var/lib/kubelet/pods # AWS_ACCESS_KEY_ID=xxxx AWS_SECRET_ACCESS_KEY=xxxx geesefs \
> --endpoint https://storage.xxxx.net \
> -o allow_other \
> --log-file /dev/stderr \
> --setuid 65534 --setgid 65534 \
> --memory-limit 1000 --dir-mode 0777 \
> --file-mode 0666 pvc-b03e3152-5f24-4361-9492-f29f662ae694 /var/lib/kubelet/pods/bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6/volumes/kubernetes.io~csi/pvc-b03e3152-5f24-4361-9492-f29f662ae694/mount
2023/12/16 02:14:26.154087 main.INFO File system has been successfully mounted.
#3. 确认挂载情况
进入 CSI Driver Pod 里,确认已经挂载成功,也可以看到 bucket 中的原有数据。
/var/lib/kubelet/pods # ls /var/lib/kubelet/pods/bc4d6f61-e748-4a64-8ab4-48a7bbfaa7f6/volumes/kubernetes.io~csi/pvc-b03e3152-5f24-4361-9492-f29f662ae694/mount
test.csv
最后,我们再次进入到业务 Pod,来看下里面的情况:
➜ kubectl exec -it csi-s3-example -- bash
root@csi-s3-example:/# ls /data
bash: cd: /data: Transport endpoint is not connected
貌似没有任何变化,为什么会这样子?

事实上我手动通过 geesefs 命令挂载的行为,仅仅只是重新模拟了 NodePublishVolume 的过程而已,它只是恢复了 Node Plugin Pod 内的挂载点。上面提到的 CSI 工作原理中 步骤 4 的行为我们并没有去触发,因此没有重新建立起业务 Pod 容器和挂载点之间的连接。
那么我们该如何解决这个问题呢?
#4. 通过 livenessProbe 来触发 Pod 的重启
如果需要将业务 Pod 中容器里的 /data 目录重新和挂载点产生连接,又不让 Pod 本身发生重新调度的行为,我们自然想到了 livenessProbe。在容器不健康情况下,它会负责检测和重启 Pod 内部的容器。
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: csi-s3-example
spec:
containers:
- name: csi-s3-example
image: nginx:1.15.2
volumeMounts:
- mountPath: /data
name: webroot
livenessProbe: # 如果挂载点 /data 不可访问或 PVC 挂载失败,判定容器不健康
exec:
command:
- ls
- /data
initialDelaySeconds: 15
periodSeconds: 20
timeoutSeconds: 5
failureThreshold: 3
volumes:
- name: webroot
persistentVolumeClaim:
claimName: csi-s3-pvc
readOnly: false
EOF
加上 livenessProbe 后,在我们主动删除掉 CSI Node Plugin Pod 情况下,可以看到业务 Pod 的状态变化,直到我们进入 CSI Driver Pod 内,手动做了geesefs挂载后,Pod 才恢复到 Running 状态。
➜ kubectl get pod -n default -owide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-s3-example 1/1 Running 0 33s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CreateContainerError 0 (1s ago) 3m21s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CreateContainerError 0 (14s ago) 3m34s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CreateContainerError 0 (27s ago) 3m47s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CreateContainerError 0 (41s ago) 4m1s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CreateContainerError 0 (56s ago) 4m16s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CrashLoopBackOff 0 (69s ago) 4m29s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CreateContainerError 0 (96s ago) 4m56s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 0/1 CrashLoopBackOff 0 (110s ago) 5m10s 100.119.66.150 local-control-plane <none> <none>
csi-s3-example 1/1 Running 1 (2m44s ago) 6m4s 100.119.66.150 local-control-plane <none> <none>
我们再次进入到业务 Pod,看!数据它又回来了,Nice 🎉🎉🎉
➜ kubectl exec -it csi-s3-example -- bash
root@csi-s3-example:/# ls /data/
abc.csv foobar test.csv
OK,思路有了后,我们就可以开始 Coding,让我们的 CSI Driver 变得更加的健壮吧,这里我就不班门弄斧了。
这其实是一个不错的思路,我司早期版本基于 NFS ganesha 的 CSI Driver 就是采用这种方案,当然里面也会有不少坑,比如使用了 subPath,就要去做一些特殊的处理。
但是这个方案,对于用户来说它的业务还是会存在中断的情况,对于平台来说,无非是将原来通过手动重启业务 Pod 的方式进化成自动化的恢复机制,仅仅只是解放了运维同事的压力,减少手动干预的需要,并不是一个好的方案。
所以,它只可以作为一种短期、紧急情况下又或者是对服务中断容忍度较高的情况下的解决办法,从更长远来看,我们应该探索更为稳定和根本的解决方案。
然而,即便我们能通过编码来增强 CSI Driver 的健壮性,还有其他方式可以考虑,以从根本上提高系统的稳定性。其中一种思路是更换挂载点的策略。
更换挂载点#
撇开 Pod 不稳定这事不说,标准的 CSI Driver 甚至不能做到平滑升级,因为它的升级必定会涉及到 CSI Node Plugin Pod 的重启 🤦,这本身是设计上的问题。
所以我们不妨换个思路,有时候防患于未然更为重要。
既然 geesefs 客户端运行在容器里容易被误杀,那么我们就调整下策略:将 geesefs 客户端直接运行在 Pod 所在的宿主机上,而非作为容器中的一部分。
这样,我们不仅减少了因容器重启导致的存储连接中断风险,而且在进行 CSI Driver 的升级时,也能避免由于重启 CSI Node Plugin Pod 而引发的服务不稳定。
值得欣慰的是,
yandex-cloud/k8s-csi-s3 默认的 Mounter: GeeseFS 已经在今年三月份的时候实现在容器外部通过 systemd 运行 geesefs 的支持,以避免在升级或重启 csi-s3 时导致挂载点崩溃。
具体实现可以参考 commit: Implement support for running geesefs OUTSIDE of the container using systemd to not crash mountpoints when csi-s3 is upgraded or restarted
root@master:~# systemctl list-units --no-pager|grep geese
geesefs-pvc_2d673864e1_2dce66_2d4d7b_2dbdf4_2dc4b3065e1e0e.service loaded active running GeeseFS mount for Kubernetes volume pvc-673864e1-ce66-4d7b-bdf4-c4b3065e1e0e
GeeseFS-based CSI for mounting S3 buckets as PersistentVolumes
思考
尽管将 FUSE 客户端直接运行在宿主机上可以提高稳定性,也能够完成平滑升级,但确实也存在一些潜在的缺点和挑战:
- 故障排查的复杂性:这种模式已经脱离了 Kubernetes 的管控,意味着其日志和监控数据可能不会被集成到 Kubernetes 的标准日志和监控系统中,所以它在可观测性的能力是比较弱的,出现了问题,只能在宿主机上排查。
- 安全方面的考虑:在宿主机上运行 FUSE 客户端可能涉及到更复杂的安全和访问权限设置。
- 资源管理:在宿主机上运行 FUSE 客户端,可能会影响宿主机的资源使用情况,特别是在资源紧张的环境中。这需要仔细监控和管理。
基于以上,在采用这种策略之前,权衡其优缺点并准备相应的管理和监控策略是非常重要的。
Sidecar 模式#
除了更换挂载点的策略,我们还可以探索一种更加灵活且创新的方法来解决 CSI Driver 的挑战,那就是采用 Sidecar 模式。这种模式充分利用 Kubernetes 的能力,提供了一种全新的视角来处理存储挑战。
在 Kubernetes 的 Pod 架构中,Sidecar Pattern 是一种流行的设计模式。它允许多个容器共享同一个 Pod 的 Network Namespace 和 Volume。正是利用了这一共享 Volume 的特性,我们可以实现一种高效且灵活的存储解决方案。
Mutating Webhook#
Sidecar 模式是一种非传统的 CSI Driver 的实现方式。我们首先通过一个例子来理解用户提交的 Pod Manifest 是如何被转换的。例如,用户提交了一个带有 PVC 的 Pod:
# 用户原始的 Pod Manifest
apiVersion: v1
kind: Pod
metadata:
name: csi-s3-example
spec:
containers:
- name: csi-s3-example
image: nginx:1.15.2
volumeMounts:
- mountPath: /data
name: webroot
volumes:
- name: webroot
persistentVolumeClaim:
claimName: csi-s3-pvc
readOnly: false
我们会在 CSI Controller Server 中注册一个 Mutating Webhook 负责处理这个 Manifest,经过处理后,用户的 Pod 会发生以下变化:
- 添加 Sidecar 容器:新增了名为
s3-mount-sidecar的容器,它位于用户定义的容器之前。这个容器的主要职责是运行 FUSE 客户端,将远程存储(如 S3 bucket)挂载到宿主机的指定路径上,同时它也负责卸载。 - 转换 Volume 类型:原本的
persistentVolumeClaim类型的 Volume 被转换为hostPath类型,这一转换使得我们可以直接在宿主机上管理存储资源,而非依赖于 Pod 内的存储挂载。事实上共有三类 Volume 会被转换:PersistentVolumeClaim、Generic ephemeral volumes以及CSI ephemeral volumes。 - 为 Sidecar 容器增加 hostPath Volume:引入了一个新的
hostPathVolumes3-dir,专门供 Sidecar 容器使用。
# 经过 Mutating Webhook 处理后的 Pod Manifest
apiVersion: v1
kind: Pod
metadata:
name: csi-s3-example
spec:
containers:
- name: s3-mount-sidecar
image: s3-mounter:v2.3.x
command:
- /project/s3-exec
- mounter
- --fuse-mount-config-dir
- /s3-mount-secret
volumeMounts:
- mountPath: /s3
# 设置为双向传播,通过这个目录传播到宿主机上
mountPropagation: Bidirectional
name: s3-dir
# 需要以特权模式运行
securityContext:
privileged: true
...
- name: csi-s3-example
image: nginx:1.15.2
volumeMounts:
- mountPath: /data
name: webroot
volumes:
# 用户容器使用的 Volume,由 mutating webhook 分配的目录
- hostPath:
path: /var/lib/s3/volume/759dabf780759fcd2553aa454ad332c0df197216/ht4hpj/webroot
name: webroot
# 当前 Pod 内 s3-mount-sidecar 挂载到宿主机上的目录,用于给不同的 volume 做数据传播
- hostPath:
path: /var/lib/s3/volume/759dabf780759fcd2553aa454ad332c0df197216
type: DirectoryOrCreate
name: s3-dir
经过 Mutating Webhook 处理后,原本的 persistentVolumeClaim 类型的 Volume 已经不复存在了。这就意味着在实际部署过程中,我们无需安装 Node Server Plugin 组件。
也正是如此,进而导致原本的编排流程中 CO 和 SP 适配的步骤需要我们自己来实现。简而言之,原本应该由 Node Server NodePublishVolume 执行的操作,现在被转移到了额外注入的 Sidecar 容器中完成。
工作原理#
Sidecar 模式的核心在于其如何实现数据的有效传播。在这里,hostPath 目录起到了数据中转站的作用。
Sidecar 容器通过 FUSE 客户端将外部存储挂载到 /s3 这个目录下,这个目录通过设置为 Bidirectional 的 volumeMounts,实现了与宿主机的数据共享。
用户的容器内通过 webroot Volume 访问的数据实际上是来自于 Sidecar 容器的远程挂载(被分配了与 Sidecar 容器相同的前缀目录)。这种方式不仅实现了数据的实时共享,而且由于存储操作被独立于业务容器之外,大大提高了系统的稳定性和可靠性。
通常情况下容器之间的共享数据都是用 emptyDir 来完成的。
针对当前的需求,如果采用 emptyDir 的话,如果业务 Pod 的 Volume 里使用了太多的 PVC,我们需要同时在 sidecar 容器里和 volume 里 mutator 出相同数量的卷出来,且还需要将业务容器的传播策略设置为 HostToContainer,整个流程会变的比较复杂。
想比较而言,hostPath 比 emptyDir 要维护的 volume 和 volumeMount 会少很多。
思考
此时有同学可能会这样问:spec.containers 这个数组內的容器之间是平等无序的,你怎么能保证 s3-mount-sidecar 里所有的挂载卷都执行完成后,才开始运行用户的容器呢?
非常好的一个问题。
目前我们是通过 lifecycle.postStart 来完成的,里面会有一个脚本,去 check 这些 mountpoint 是否已经 ready。
...
lifecycle:
postStart:
exec:
command:
- bash
- -c
- /check-mountpoint.sh
preStop:
exec:
command:
- bash
- -c
- sleep 20
...
值得一提的事,在 Kubernetes v1.29 发布后,现在 SidecarContainers 特性达到 Beta 并默认启用了,或许我们可以尝试来使用它了。我们现在这种情况,对于 Job 类型的工作负载,如果挂载了 PVC 的话,在 Job 完成的时候,还需要特意再发一个 TERM 信号才能让我们注入的 sidecar 容器退出。
apiVersion: v1
kind: Pod
metadata:
name: csi-s3-example
spec:
initContainers:
- name: s3-mount-sidecar
image: s3-mounter:v2.3.x
restartPolicy: Always
...
因为 Sidecar containers 的停止顺序将按照与它们启动时候相反的顺序来进行,这样一方面可以确保是主容器先停止的,另一方面也便于控制所有组件的生命周期。
收益#
这种方案,最直接的好处就是,每个业务 Pod 都有自己的 Sidecar 容器, 不同的挂载点之间是完全隔离的,也正因为挂载点是在 Sidecar 容器里进行的,所以 CSI Driver 自然能够做到平滑升级了。
另外它的可观测性也增强了,哪个业务 Pod 出现了问题,我们只需看对应的 Sidecar 容器就行,不需要再关注宿主机。
当然,同时带来的问题是开销也变大了,哈哈,但是从另外一方面来讲,这个方案资源分配也可以更加的合理,有利有弊吧。
写在后面#
在 Kubernetes 的快速发展过程中,CSI Driver 作为连接容器和存储系统的桥梁,其稳定性和可靠性对于整个系统至关重要。本文通过分析挂载点失效等典型问题,探讨了从传统的解决方案到创新的 Sidecar 模式的多种应对策略。这些策略不仅为开发人员和系统管理员提供了宝贵的实践经验,还展示了 Kubernetes 生态系统的灵活性和可扩展性。
随着技术的不断进步,我们期待看到更多高效且稳健的解决方案,以应对未来可能出现的新挑战。
好了,今天的分享就到这里,感谢你的阅读!🙌🏻😁📃 期待我们的下次见面!👋🚀
References#
