Kubernetes Storage 101: 浅谈 Kubernetes 存储概念,解锁数据驱动的力量
Table of Contents

Kubernetes 可以说是已经成为云原生分布式操作系统的事实标准了,它最大的优势在于可扩展性,不论是计算、存储还是网络,它都可以根据使用者的需求来进行灵活扩展。
我曾在团队内部就 Kubernetes Storage 主题做过分享,内容较为基础,旨在激发大家的思考。今天我将通过文稿的形式将这些分享整理出来,重新阅读时,我发现自己从中收获了很多,希望对其他朋友也能有所帮助。
由于篇幅较长,我们将从 Kubernetes 存储的基本概念和术语开始。
为什么说 Kubernetes 存储很重要?#
对于开发工程师来说,Container 想必大家都已经不陌生了。
Container 它本质上是无状态的,且内容存在的时间极为短暂。一旦容器关闭,它就会回到最初的状态。这就意味着在容器处于活动状态时,由应用产生的数据也就丢掉了。
存储可以说是支撑应用的一个基石,数据若没了,应用必定无法正常工作,所以这种情况对于应用来说肯定是不能够被接受的。
随着应用逐渐往云原生转型,让我们来看下应用在上 Kubernetes 平台都会碰到哪些存储问题。
#1. 应用的配置#
每个应用程序都有它自己的配置,通常的做法是将配置和代码解耦,保持其灵活性。应用代码走镜像,那么配置在 Kubernetes 里又是如何处理的呢?
#2. 容器间数据通信#
Pod 作为 Kubernetes 里的最小部署单元,Pod 里多个容器内的数据共享怎么做?又或者说微服务架构下不同节点上的 Pod 数据又是如何做通信的?
#3. 容器内数据持久化#
Pod 是非常脆弱的,如果 Pod 挂了,做了重新调度,应用在旧 Pod 里写的数据还能找回吗?
#4. 集成第三方存储服务#
比方说我们有自己的存储服务,又或者说有客户要求必须使用国产的某个存储系统,这个时候我们有没有办法可以将它们集成到 Kubernetes 的存储体系里?
解决方案#
为了解决以上这些问题,Kubernetes 引入了 Volume 这个抽象的概念。用户只需通过资源和声明式 API 来描述自己的意图,Kubernetes 自会根据用户的需求来完成具体的操作。
Volume 一词它最初来源于操作系统的术语,在 Docker 中也有类似的概念。在 Kubernetes 世界中,Volume 是指一种可插拔的抽象层,用于在 Pod 和容器之间共享和持久化数据。
本篇文章我们将一起探讨 Kubernetes 中 Volume 的概念与应用。
Kubernetes 存储体系#
我们知道存储技术的种类非常多,Kubernetes 为了尽可能多地兼容各种存储,因此它预置了很多插件,它将选择权交到了用户手里,让用户根据自己的业务需求来选择。
kubectl explain pod.spec.volumes
这个命令将返回一个关于 Kubernetes Pod 中 Volume 定义的详细说明,包括其字段和用法,它可以帮助用户了解如何在 Pod 中定义一个 Volume。
使用上述命令,我们可以发现 Kubernetes 默认支持了至少 20 多种存储卷类型,这些存储卷类型可以满足各种不同的存储需求。这个特性使得 Kubernetes 在存储方面非常灵活,并且可以适应各种应用程序的存储要求。
下面这张表格是根据存储插件的种类,做的 2 个大类,表格里只列出了比较常用的卷类型,但还有其他类型可以在官方文档的 Types of Persistent Volumes[1] 中找到。
如果有对 In-Tree Volume[2] 的实现感兴趣的同学,可以查看源代码。

那么 In-Tree 和 Out-Of-Tree 两者有什么区别呢?我们可以从字面上先大致理解一下它们的区别,后续我会详细介绍它们的不同之处。
可以将 In-Tree 理解为将实现代码放在 Kubernetes 代码仓库中;而 Out-Of-Tree 则表示代码实现与 Kubernetes 本身解耦,存放在 Kubernetes 代码仓库之外。
小结
乍一看,Kubernetes 支持的存储卷类型太多了,对于不熟悉的同学可能感到无从下手。然而,总结起来其实主要有两种类型:
非持久化的 Volume(Non-Persistent Volume or also called ephemeral storage)
持久化的 PersistentVolume
Non-Persistent Volume vs Persistent Volume#
在介绍这两种 Volume 的主要区别之前,我觉得有必要声明一下它们的共同点:
1. 使用方式
首先都是通过在
.spec.volumes[]里定义使用哪一种 Volume 类型然后将其挂载到容器的指定位置
.spec.containers[].volumeMounts[]
2. 宿主机目录
不论是哪种 Volume 类型,Kubelet 都会为调度到当前 HOST 上的 Pod, 创建它的 Volume 目录,格式如下
/var/lib/kubelet/pods/<Pod-UID>/volumes/kubernetes.io~<Volume-Type>/<Volume-Name>
#1. Non-Persistent Volume#
设计 Non-Persistent Volume 的目的并非为了持久的保存数据,它是为同一个 Pod 中多个 Container 之间提供可共享的存储资源。
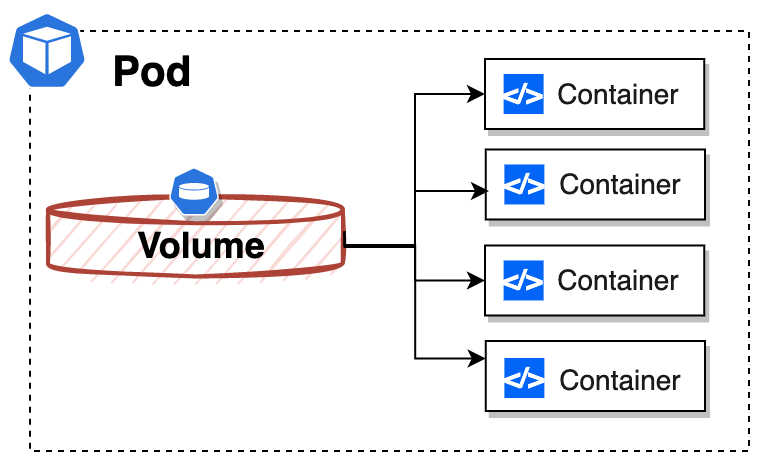
从上面的架构图可以看出,Volume 是包在 Pod 内的,因此其生命周期与挂载它的 Pod 是一致的。
当 Pod 因某种原因被销毁时,Volume 也会随之删除,但至少它的生命周期要比 Pod 中运行的任何一个容器的存活时间长。
思考
以下是 Kubernetes 官方文档对 Pod 生命周期的描述
Pods are only scheduled once in their lifetime. Once a Pod is scheduled (assigned) to a Node, the Pod runs on that Node until it stops or is terminated.
对于配置了 restartPolicy != Never 的 Pod,即使发生异常导致 Pod 重启,Pod 本身不会重新调度,因此这些 Volume 的数据其实都还在,因为 Pod 的 UID 并未发生变化,它并没有被删除。
除非被 Kubelet GC 回收机制清理掉了。
#2. Persistent Volume#
设计 Persistent Volume 的目的是为了持久的保存数据,且它能为不同节点上的 Pod 中多个 Container 提供可共享的存储资源。
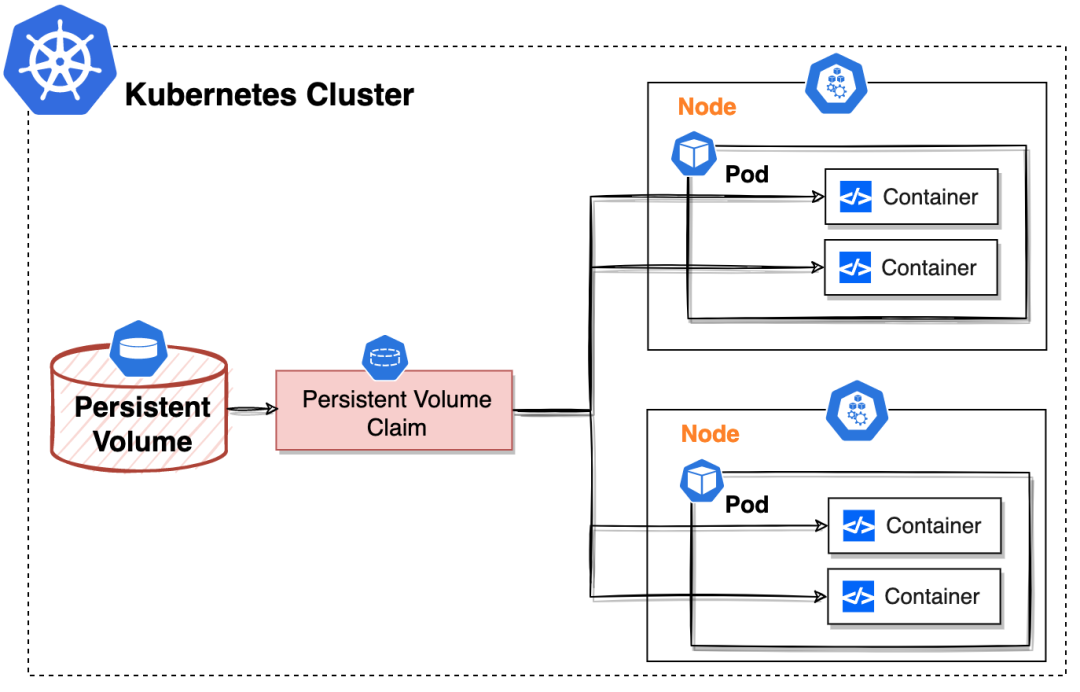
很明显,从上面的架构中看到 Persistent Volume 是独立于 Pod 存在的,所以它的生命周期与 Pod 是无关的。
ConfigMap/Secret & EmtpyDir & HostPath#
下面简单过一下 Kubernetes 平台经常用到的都有哪些存储卷,我们先站在使用者的角度去看这些存储卷都是怎么使用的?
这三种类型我在前面的文章里也都分享过,只是没有特意强调存储这个概念。现在我将它们放在一起,或许可以让大家更深刻理解到它们的适用场景。
ConfigMap/Secret 适用场景#
ConfigMap 和 Secret 这两个资源通常用来存储应用程序的配置,是 Kubernetes 平台作为解耦配置和代码的一种常用手段。
最佳实践#
我们可以将它们当做一个存储卷来使用,下面是一个比较常见的用法,详细内容可以点击图片直接跳转查看。

EmtpyDir 适用场景#
EmtpyDir 可以说是一种很常用的 Volume 了,顾名思义,它刚被创建出来的时候是一个空目录,通常被用于 Pod 内多个容器之间的数据共享。
它属于 Non-Persistent Volume,Pod 被删除时,在 EmtpyDir 内生成的数据也一并会被清除。
最佳实践#
我们以下面这个架构举例,其中 Init Container 用来作数据的准备容器,负责写内容;Application Container 作为主应用的容器,负责数据的读取。
该例子不仅诠释了 Kubernetes 容器编排的魅力,同时它也是富容器的一种解决方案,具体可以点击图片查看详细内容 Scenario 03
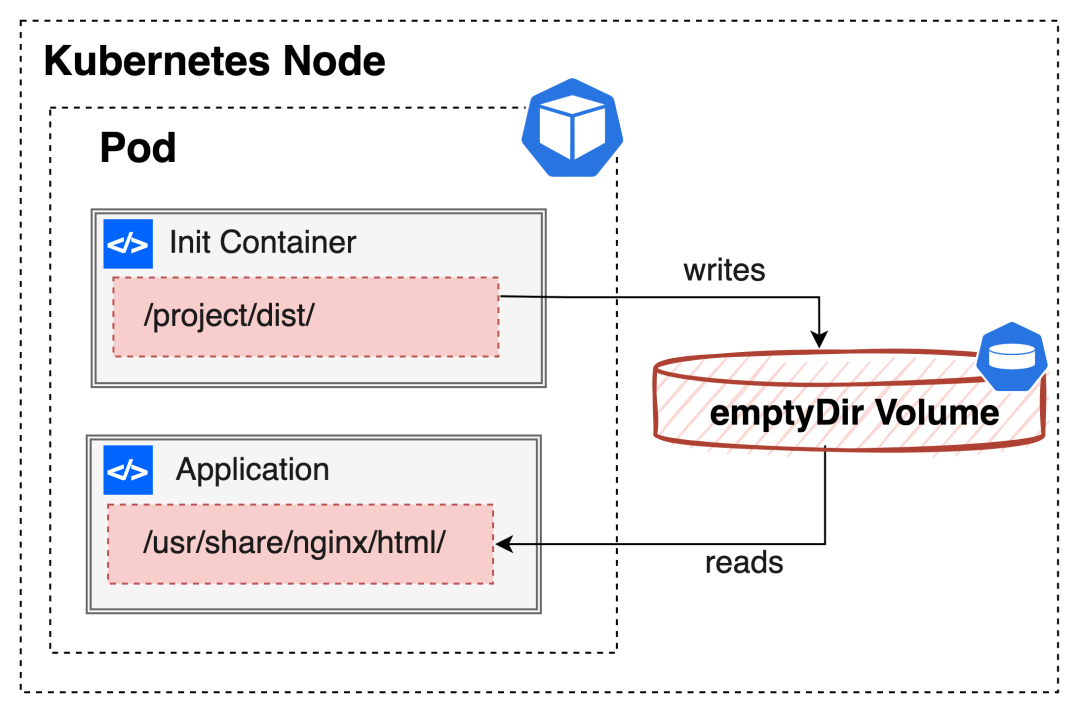
我们再来看另外一个比较常见的例子,sidecar 容器通过 EmtpyDir 来读取另外一个容器的日志文件。
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: lqshow/busybox-curl:1.28
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-sidecar
image: lqshow/busybox-curl:1.28
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
EOF
正如大家所见,Pod 里 count 容器的日志并未以 stdout 的方式输出,我们若想用以下命令其实是抓不到日志的。
kubectl logs -f counter -c count
但是我们可以通过一个 sidecar 容器,将日志文件读出来重新以 stdout 的方式输出来。
当然这种处理日志的方式肯定不是最佳的,因为它会导致宿主机上会形成 2 份一样的日志,其实完全没有必要的。但是这里举这么一个例子用来帮助理解 emptyDir 的适用场景,我是觉得还蛮合适的。
kubectl logs -f counter -c count-log-sidecar
HostPath 适用场景#
HostPath 它是将宿主机节点上的文件系统上的文件或目录,直接挂载到 Pod 中的,另外需要注意的是卷数据是持久化在宿主机节点的文件系统内的。
这种 Volume 类型其实不适合大部分的应用,因为 Volume 里的内容它只保留在某个特定的节点上,一旦 Pod 做了重新分配,调度到了其他节点,原数据是不会被带过来的。
所以一般情况下不建议使用 hostpath,除非你有一个非常具体的需求,并且了解你在做什么,是否 make sense?
最佳实践#
HostPath 通常和 DaemonSet 搭配使用,我们继续以上面提到的日志收集为例,每个节点上会跑一个 Logging agent(Fluentd),它会挂载宿主机上的容器日志目录,来达到收集当前主机日志的目的。
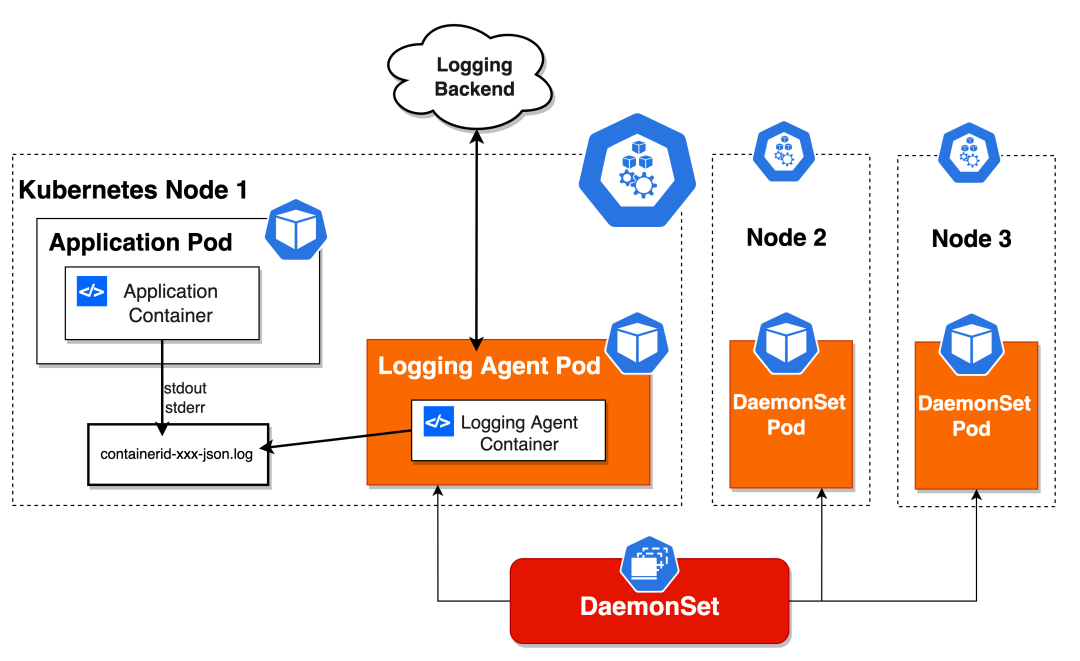
还有我们本次分享的主题之一,各种存储插件的 Agent 组件(CSI),它也必须运行在每一个节点上,用来在这个节点上挂载远程存储目录,操作容器的 Volume 目录。
当然它还有很多其他用法,大家自己去发现啦,我就不在多做介绍了。
思考#
HostPath + NodeAffinity 虽然能做到伪持久化,看似有了 PV 的能力,但是我们不建议这么使用,因为这种方式很容易会将宿主机上的磁盘写满,最终会导致当前节点 NotReady。
另外出于对集群安全的考虑,我们通常都会限制 HostPath 挂载,毕竟 HostPath Volume 存在许多安全风险,如果不加以限制,用户真的有可能对 Node 做任何事情。
PV,PVC & Storage Class#
PV 和 PVC 是 Kubernetes 存储体系里非常重要的两个资源,它们的引入主要是为了实现职责分离和解耦。
这么说吧,对于应用开发者来说,他们无需关心存储设施的细节,只需关注应用对存储资源的需求。
其实还有一个原因,作为开发者的我们并不知道集群里有哪些 volume 类型可用,而且存储相关的配置也确实非常的复杂。
存储涉及的知识领域很专业,俗话说让专业人做专业事,可以更好的提高做事效率。
我们先来看下官方对这两个资源的解读吧。
名词解释#
#1. Persistent Volume#
Cluster 级别的资源,它由集群管理员或者是External Provisioner组件创建。
它描述的是持久化存储数据卷。
#2. Persistent Volume Claim#
Namespace 级别的资源,它由开发者或者是StatefulSet控制器(根据 VolumeClaimTemplate) 创建,另外通用临时卷(Generic ephemeral volume)也会创建其生命周期与 Pod 一致的临时存储卷。
它描述的是 Pod 对持久化存储的需求属性,如 Volume 的容量、访问模式等,提供了对底层存储资源的抽象表述。
通过使用 PVC,可以使 Pod 跨集群移植成为可能。
#3. Storage Class#
Cluster 级别的资源,它由集群管理员创建,它定义了动态供应和配置 PV 的能力。Storage Class 提供了一种动态分配 PV 的机制,根据 PVC 的请求自动创建 PV,并实现了存储的动态供应和管理。
这里有必要提一下 StorageClass 中的 parameters 字段,它虽然是一个可选的字段,用于指定与存储类相关的参数,但是在开发 CSI Driver 的时候,这个参数非常的有用,具体参见:Secrets and Credentials[3]。
这些参数的具体含义取决于所使用的存储插件和存储供应商。
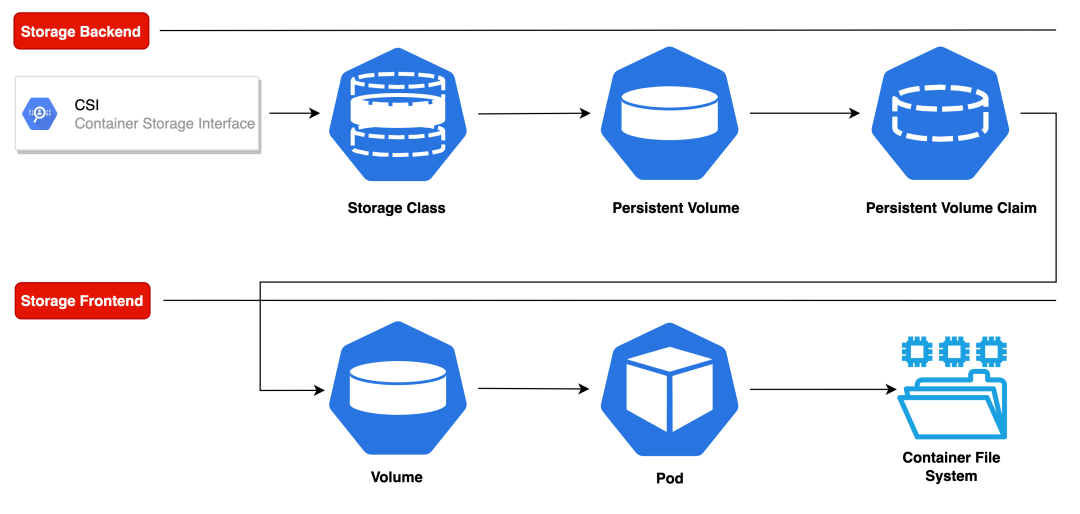
怎么理解呢?#
对于刚接触 Kubernetes 不久的同学来说,仅从名词解释上可能不大好理解。
一开始我也感到困惑,不知道这些资源是什么,如何使用,以及它们适用的场景。

没关系,接下来我们将从不同角度对这些资源进行解读,希望能帮助大家建立概念。最后,我会介绍它们的具体用法。
#1. 从资源维度#
以下是一个恰当的比喻,虽然出处未知,但我觉得很适合,所以直接引用了
PV 资源的 .Spec 中保存了存储设备的详细信息,我们可以把 PVC 想象成 Pod。
Pod 消耗 Node 资源,而 PVC 消耗的是 PV 资源
Pod 可以请求特定级别的资源(比如 CPU 和内存),而 PVC 可以请求特定存储卷的大小及访问模式
PVC 将应用程序与它背后特定的存储做解耦
#2. 从关注点分离维度#
应用开发者#
首先需要明确的是,对应用开发者来说,我们只会跟 PVC 这个资源打交道,因为只有我们开发者才知道自己的应用大概需要多少存储空间。
在 Kubernetes 中,PVC 可以被视为持久化存储的抽象接口。它描述了对特定持久化存储的需求和属性,但并不负责实际的存储实现。PV 负责实现具体的存储,并与 PVC 进行绑定。
我们只需要明确自己的需求,即存储需要的大小以及访问模式就够了,而不必关心存储背后具体是 NFS 还是 Ceph 等实现方式,这并不是我们需要关心的事情。
这种分离的设计让我们能够专注于应用开发,无需关心底层存储技术的选择和实现,从而提高我们的效率和灵活性。
运维人员#
PV 资源通常是由运维人员来创建的,因为集群内会提供哪些存储,也只有集群运维人员才知道,这个应该比较好理解。
Provisioning#
集群内提供 PV 一般有两种方式,下面我们来分别看下这两种方式的优缺点
#1. Static Provisioning#
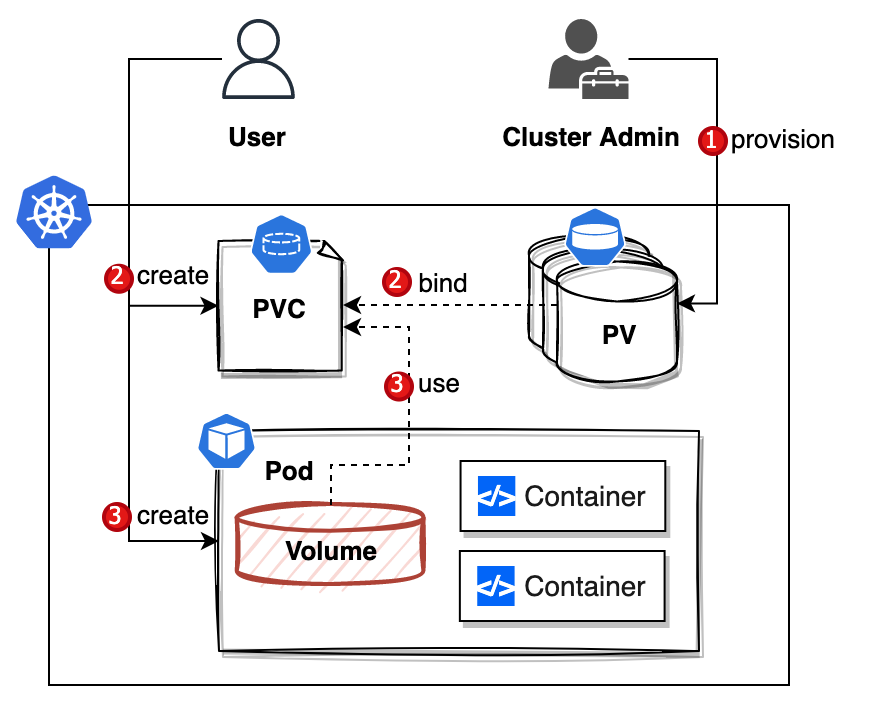
使用流程#
首先由集群管理员基于一些底层网络存储资源创建一个静态持久化卷
然后用户创建一个 PVC 声明,用来申请第一步的特定持久化卷
最后创建一个 Pod 并同时使用这个 PVC

思考#
这种方式好处是非常明显的,可以说集群内所有的存储资源都在运维的掌控中。
但是,供给静态 PV 这种流程,PV 资源必须是由运维人员参与创建的,它也带来一些问题:
小规模的集群还好,如果在大规模的生产环境下,用户应用的实例是不可控的,可能需要成千上万个 PV,无法预测。这种手动且重复的工作,效率不仅低下,且这种操作对管理员也是一种痛苦。
另外这种方式也很容易导致存储使用效率低下
要么配置少了,限制程序的运行
要么过度配置了,导致存储的浪费
那么如何实现自动化呢?这就得依赖 Storage Class 这个概念了,它引入了动态存储配置的流程。
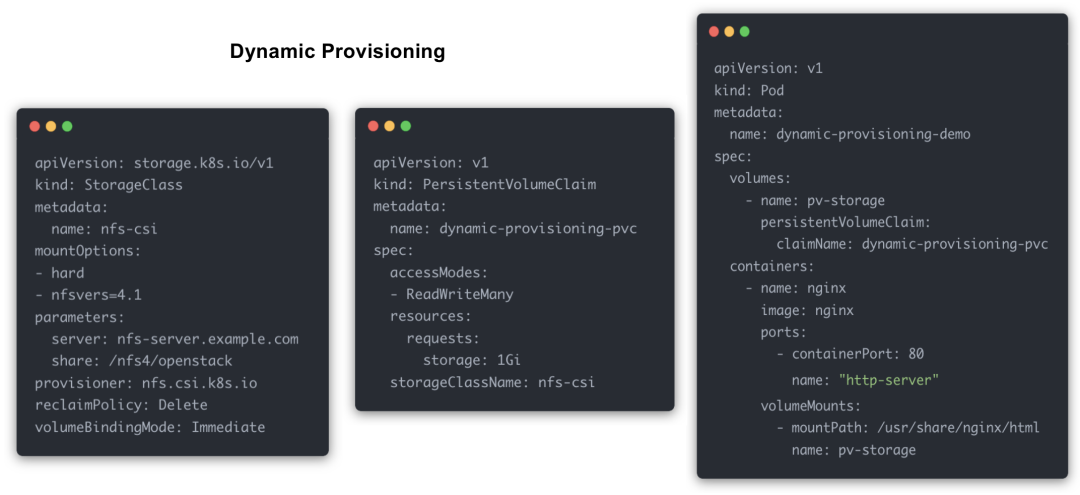
#2. Dynamic Provisioning#
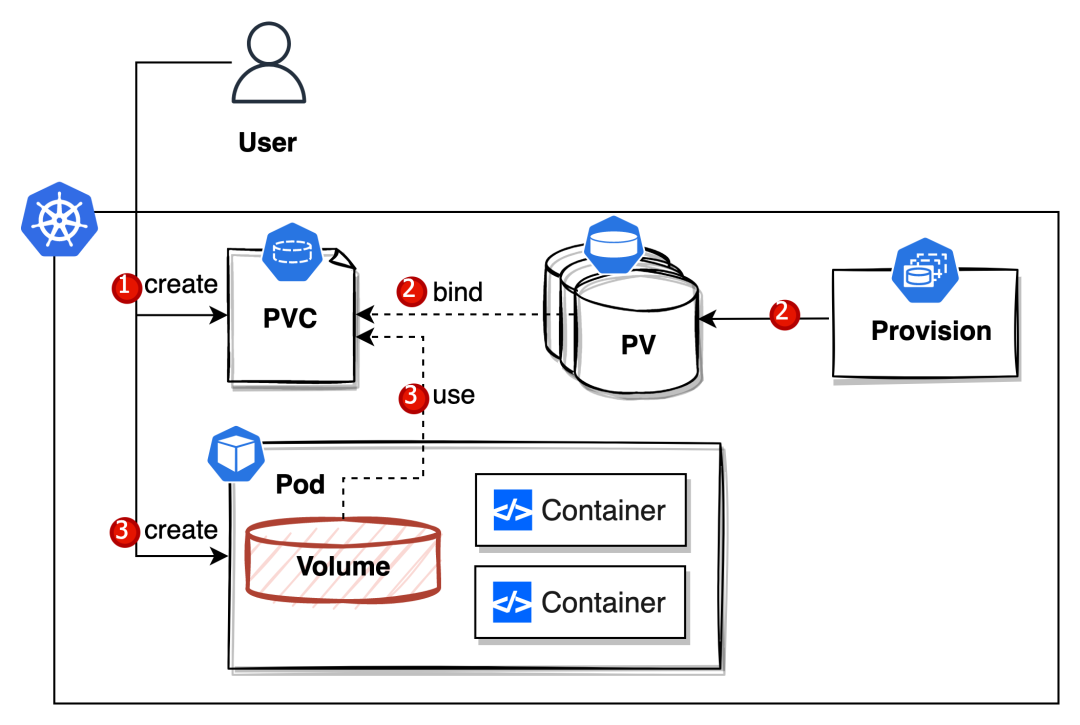
使用流程#
从上面的流程图来看,很明显整个流程少了管理员的介入。
用户创建一个 PVC 的时候,由对应的 Provision 自动创建一个 PV 与它进行一一绑定。怎么对应呢?就是通过 storageClassName 来寻找。
创建一个 Pod 并同时使用这个 PVC,这个流程两者都是一致的。
思考#
自动创建 PV 这种模式,它可以说是完全改变了部署的工作方式。
它其实不仅仅是解放了运维人员这么简单,对 DevOps 的推进也提供了很大的帮助。
PV 和 PVC 绑定条件#
- StorageClass: PV 和 PVC 必须属于相同的 StorageClass。
- 访问模式(Access Modes): PV 和 PVC 的访问模式必须兼容,访问模式定义了 Pod 如何访问存储卷。
- 容量(Capacity):PVC 的请求容量不能超过 PV 的容量。PVC 可以请求一个特定大小的存储卷,而 PV 必须具备足够的容量来满足 PVC 的请求。
- Selector(选择器): PV 可以定义一个或多个 Label Selector,而 PVC 可以通过 Label Selector 来选择匹配的 PV。PVC 的 Selector 必须匹配 PV 的 Label Selector 才能进行绑定。
当满足这些绑定条件时,Kubernetes 将会自动将 PVC 绑定到相应的 PV 上,从而实现持久化存储的分配和使用。
思考#
在 Kubernetes 中,PV 与 PVC 是一对一的关系,一个 PV 只能绑定一个 PVC。然而,多个 Pod 可以共享同一个 PVC,从而使用该 PVC 提供的持久化存储。
事实上,我们在生产环境并不会直接使用 Pod,因为它会因为各种原因被关闭而不再提供服务,比如被节点驱逐。
一般情况下我们使用 Deployment, 它可以管理多个副本(replicas)的 Pod,在以下场景中,我们有 3 个 Pod 副本,它们挂载同一个 PVC,如果该 PVC 只有只读权限的话,那么不会出现任何问题。
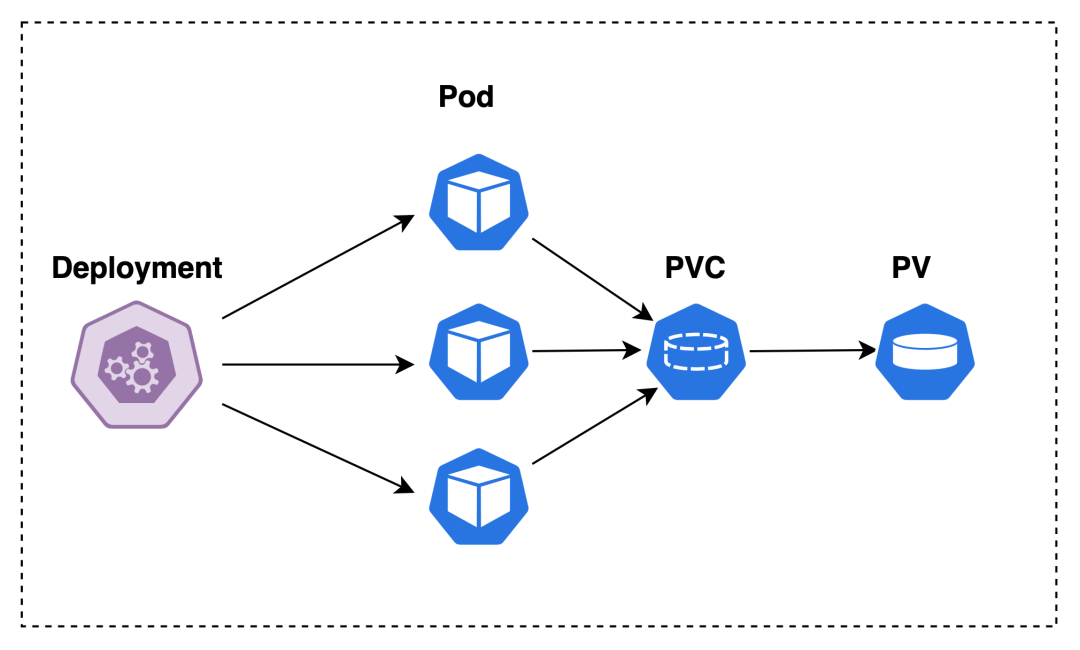
但是,如果该 PVC 具有读写权限,然后又被 3 个 Pod 副本共享,这可能会导致数据不一致的问题。
好比说会碰到 Race Condition:如果两个或更多的 Pod 同时写入相同的文件,可能会发生数据覆盖或者数据不一致的情况。
那么有什么办法可以解决这个问题呢?那就是 StatefulSet 工作负载,它也有多副本的概念。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
...
replicas: 3
template:
...
volumeClaimTemplates: # 定义创建与该 StatefulSet 相关的 PVC 的模板
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "my-storage-class"
resources:
requests:
storage: 1Gi
不同之处我们可以通过定义 volumeClaimTemplates,以便自动为每个副本创建一个新的 PVC,如下图所示
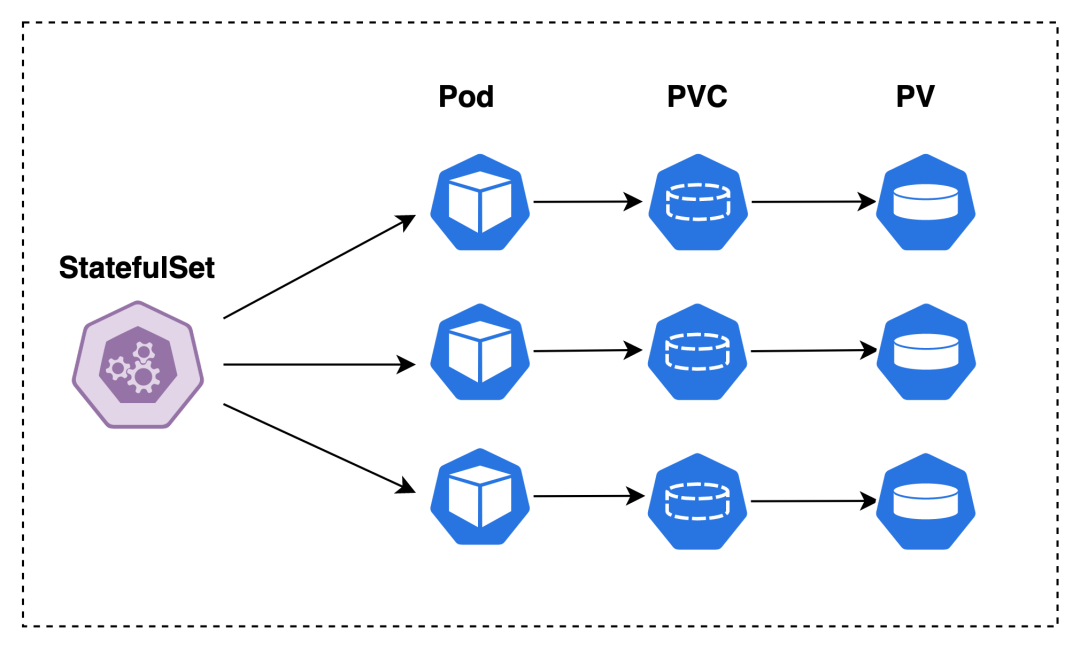
当然,实际场景往往会更加的复杂,尤其是分布式应用,如主从关系需要考虑 StatefulSet 提供的 Pod 标识与顺序等特性。
我们再来看一下 PVC 最后一种创建方式:它就是通用临时卷(Generic ephemeral volume)。
需要注意的是,Generic Ephemeral Volume 中的数据只会在容器的生命周期内保留,当 Pod 被删除或重启时,一并生产的 PVC 同时也被删除。
因此,Generic Ephemeral Volume 适用于需要在容器生命周期内保留一些临时数据的场景,例如缓存文件或临时配置文件。
kind: Pod
apiVersion: v1
metadata:
name: my-app
spec:
containers:
- name: my-frontend
volumeMounts:
- mountPath: "/scratch"
name: scratch-volume
...
volumes:
- name: scratch-volume
ephemeral:
volumeClaimTemplate:
metadata:
labels:
type: my-frontend-volume
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "scratch-storage-class"
resources:
requests:
storage: 1Gi
Default Storage Class#
管理员可以将集群内的某个存储类打上 annotation,作为 Default Storage Class,它是预定义的一种特殊存储类,用于指定在未显式指定存储类的情况下所使用的默认存储类。
kubectl patch storageclass <STORAGE-CLASS-NAME> -p \
'{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
Container Storage Interface#
尽管 Kubernetes 平台本身支持多种存储插件,但由于用户需求不断增长,这些插件往往无法满足所有要求。比方说,当客户要求我们的 PaaS 平台必须与国产某个存储集成时,我们该如何应对?
此外,这些存储插件基本上是 In-tree的,如果插件需要做 patch,当前的模式会给测试和维护带来不便。
这时就不得不提到容器存储接口(CSI),它本质上只是定义了一套协议标准,第三方存储插件只要实现这些统一的接口,就能对接 Kubernetes,用户无需接触核心的 Kubernetes 代码。
适配工作由容器编排系统(如 Kubernetes)和存储提供商(SP)共同完成,CO 通过 gRPC 与 CSI 插件进行通信。
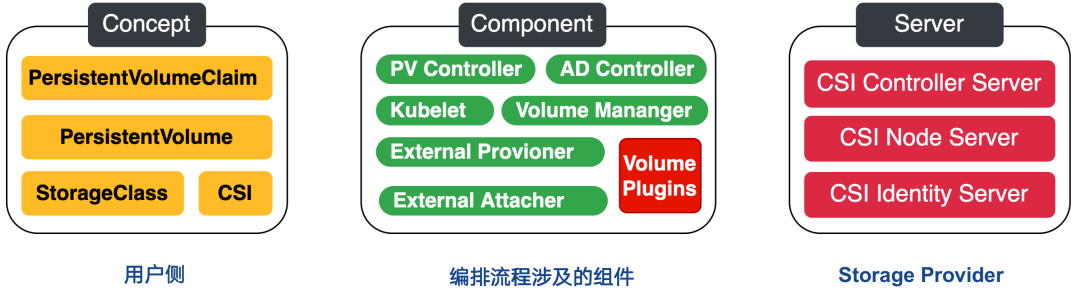
CSI 其实蛮复杂的,涉及到的组件相当多,后面我会专门写一篇文章介绍 CSI 的工作原理以及遇到的挑战。
写在最后#
通过对这些基本概念的理解,我们能够在 Kubernetes 中正确配置和管理存储资源,满足应用程序对持久化存储的需求。
下一期,我将继续与大家分享 Kubernetes 持久化存储流程的实现方法。
