Cloud Native 101: 一文掌握如何高效上云,开启云原生之旅(上)
Table of Contents

现在云原生技术在火热发展,那么什么是云原生呢?在每个不同的阶段,每个人对它的理解和定义都是不同的。
以下是 CNCF 的技术监督委员会 给云原生做出的定义
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式 API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
云原生计算基金会(CNCF)致力于培育和维护一个厂商中立的开源生态系统,来推广云原生技术。我们通过将最前沿的模式民主化,让这些创新为大众所用。
我们先来看一张 CNCF 提供的云原生全景图,不难发现云原生技术生态圈太庞大了,而且它还在不断的蓬勃发展中…👍🏻👍🏻👍🏻

云原生其实是一套实践和方法论,它是用来指导用户进行软件架构设计的思想。云原生可以说是抽象、抽象、再抽象,在很大程度上减轻了用户的心智负担。
为什么要上 Kubernetes?#
先说一则小故事。
我有一个朋友,他们公司并不是所有的产品线都上了 Kubernetes,有的产品线仍采用 Docker Swarm 来部署应用。
去年他接到过一个需求:“协助一个团队,将他们内部的一个微服务应用集成到 Kubernetes 中”,当时跟我朋友对接的是其他团队的一个新人,对于 Kubernetes 只处于听说过的阶段,并没有上手实践的经验。
他们采用 Helm 来管理应用内 Kubernetes 的各个资源,内网已经有了适配各类型应用的模板了,CI/CD 也做的非常成熟,所以至少在我看来将应用迁移到 Kubernetes 中,还是非常方便的,都是套路,抄抄作业罢了。
我朋友说他花了一天时间和那位新同事讲解了一些基本概念和各种套路方法,以为很快能搞定。
但是事实上并非如此,那位同事后来搞了好久,Deadline 快临近了还没弄完。

后来他们的 Leader 发出了灵魂拷问,业务侧的需求很简单,X 服务只要能访问到我们的接口就行,为啥我们非要上 Kubernetes ?
那时我才明白,原来需求到我朋友这的时候,和原需求的方向有点偏差了,这其实就是 X-Y PROBLEM 的一个变种,至于后面怎么处理那件事就是另外的故事了…
其实这只是个小笑话了,但是从另外一个方面也说明了一个很大的问题,可能也是大部分人的疑问吧。
“我只是想部署一个应用而已,非要上 Kubernetes 平台吗?上 Kubernetes 对我的应用有什么价值呢?”

将应用集成到 Kubernetes 中来,或许对于 Kubernetes 平台开发工程师来说没有任何心智负担,但是对于一个普通的应用开发者来说,你如果没有好好的去了解它的概念,还真一时半会弄不起来,因为在 Kubernetes 的世界里它没有应用的概念,有的只是各种抽象,还有它的学习曲线。
确实,这个问题很难回答,你说我们的系统在线上跑的好好的,没出任何问题,它又不是不能用了?为什么要迁?
其实这个和 Kubernetes 的定位有关,它其实并不是直接面向应用开发者的,它是一个标准化的能力接入层,它的专注点是如何将一些底层基础设施抽象出来,然后再通过标准化的声明式 API 暴露出来,将选择权交给了用户。
所以,Kubernetes 实际的用户并不是业务开发者,也不是应用开发者,而是我们的平台开发者,它给平台开发者提供了各种解决方案。
也正是因为这个原因,Kubernetes 逐渐成为云原生体系的操作系统。
根据 SlashData 为 CNCF 开发的最新的云原生开发报告,Kubernetes 在过去的 12 个月里已经展示了令人印象深刻的增长——现在有 560 万开发者使用 Kubernetes。这比一年前增长了 67%,当时全球有 390 万 Kubernetes 开发者。这一群体现在占所有后端开发者的 31%,比去年增加了 4 个百分点。
迁移应用到 Kubernetes#
既然 Kubernetes 现在已经成为了事实上的云原生分布式操作系统,那么应用程序从设计之初就需要考虑到如何上 Kubernetes,另外对于一些旧应用需要怎么做才能迁移到 Kubernetes 里面,相信这点也是每一位开发者最关心的事情。
在 Kubernetes 的世界中一切皆资源,任何东西都是用资源来描述的。但是也正因为概念多,太细,对于新手来说,可能会有些困惑,往往不知道从哪里开始。
一般处于不同角色的工程师,往往他们所关心的点都是不同的,比如应用开发者关注业务逻辑,运维工程师关注应用如何方便的上线。
本篇文章尝试从关注点分离出发,帮助新手们捋顺你们所关心的东西,在 Kubernetes 世界里都代表着什么?
Role of an App Developer#
首先作为一个应用开发者,肯定最关心的是如何将现有的应用程序以最小的成本迁移到 Kubernetes 集群中,下面罗列的是 Kubernetes 中与应用开发者关系最密切的几个资源对象。
配置文件#
网络访问#
Role of an App Operator#
在我看来,对应用该怎么交付,以什么样的方式来部署,应用开发者自己心里其实是最清楚的,你不可能说我开发完了,直接将一个镜像交给运维让他们来弄就完事了,这显然是不现实的。
所以,为了区分应用开发者的角色,这里我用应用运维来定义这个角色,下面几个 Kubernetes 资源对象是该角色需要去了解的。
控制器编排#
数据持久化#
暴露应用#
账号角色#
Role of an App Developer#
① 配置#
每个应用程序都有它自己的配置,通常的做法是将配置和代码解耦,保持其灵活性。
举个例子。
在生产环境运行中,你收到客户的需求让做一部分调参,如果将配置做了 hardcode,你还不得重新构建应用程序的镜像,这个是非常耗时的,最重要的还需要重新走审核升级流程。
如果你事先将配置和镜像做了解耦,只需要给客户的环境做下配置定制即可,分分钟钟就能够解决问题。
#1. 环境变量#
环境变量是将应用程序和配置解耦的常见做法,The Twelve-Factor App 也推荐将应用的配置存储于环境变量中,在 Kubernetes 中有如下几种做法
1). 在 Spec 中,直接为容器设置环境变量,名值对方式#
spec:
containers:
- env:
- name: MY_STRING
value: hello-world
- name: MY_INTEGER
value: "5432" # 值为数字需要加上双引号
- name: MY_BOOLEAN
value: "true" # 值为布尔型需要加上双引号
2). 从 ConfigMap 中获取(用于非敏感配置)#
我们可以事先将环境变量的键值对,写入到 ConfigMap 这个资源中,通过使用 ConfigMap 来将配置和代码解耦,方便应用配置的随时修改。
首先创建一个 ConfigMap。
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
NODE_ENV: production
DEV_MODE: "false"
PORT: "3000"
EOF
全部写入:在 Spec 里通过 envFrom 关键字直接将以上定义的名为 app-config 的 ConfigMap 的键值对全部写入到环境变量中,它的键就是环境变量的名称
spec:
containers:
- envFrom:
- configMapRef:
name: app-config
按需写入:按需选择指定的 Key 写入到容器的环境变量
spec:
containers:
- env:
- name: FROM_CONFIGMAP_KEY
valueFrom:
configMapKeyRef:
name: app-config # ConfigMap 的名称
key: NODE_ENV # ConfigMap 中的键
3). 从 Secret 中获取(用于敏感配置)#
创建一个 Secret
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: app-secrets
type: Opaque
data:
MYSQL_USER: cm9vdAo=
MYSQL_PASSWORD: dGVzdDEyMzQK
EOF
全部写入:在 Spec 里通过 envFrom 关键字直接将以上定义的名为 app-secrets 的 Secret 的键值对全部写入到环境变量中
spec:
containers:
- envFrom:
- secretRef:
name: app-secrets
按需写入:按需选择指定的 Key 写入到容器的环境变量
spec:
containers:
- env:
- name: FROM_SECRET_KEY
valueFrom:
secretKeyRef:
name: app-secrets # Secret 的名称
key: MYSQL_USER # Secret 中的键
⚠️ 小结以及一些注意项
- 直接在 Spec 里设置环境变量虽然方便,但脱离于容器,采用集中化管理环境变量的方式更好,建议使用 ConfigMap/Secret
- 引用 ConfigMap/Secret 的资源需要和被引用的 ConfigMap/Secret 在同一个 namespace 下
- ConfigMap 中存储的是明文的数据,机密性数据可以通过 Secret 来做,但是 Secret 其实也只是做了 base64 编码而已,很轻易的能解出来,所以一些真正敏感的配置,还是需要用一些社区提供的第三方插件来做
- 建议将 ConfigMap/Secret 里用作环境变量访问的键,用纯大写的方式来处理
- 如果 container 中存在多份 envFrom, confingMap 中相同的键会被后面的替换。
#2. 配置文件#
环境变量使用起来非常方便,但是它只有在应用启动前被设置,待应用程序启动后就不能再做调整了,所以在某些使用场景下有一定的局限性,因为它不支持热更新,只有重新删除了 Pod,重启应用后才能生效。(这块其实一直存有争议,在某些场景中确实需要这种不可变性)
那么在 Kubernetes 里,有没有一种在应用运行时,通过更改外部配置,即可实现热更新呢?
有的,我们还是用 ConfigMap 和 Secret 这两个资源,只不过配置注入到应用程序的方法做了调整,采用 Volume 挂载的形式。
1) ConfigMap 映射到卷#
我们可以将 ConfigMap 当做卷来使用,其中的键可以映射成容器内的文件名,值为文件的内容
创建 ConfigMap
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
game.properties: |
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
EOF
将整个 ConfigMap 映射成卷,所有的键映射成文件,挂载到容器内
spec:
containers:
- volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: app-config
可以看到在容器内 /etc/config 目录下生成了 2 个文件,文件名分别对应的是 ConfigMap 的键名
➜ kubectl exec -it hello-world -- ls -lha /etc/config
total 12
drwxrwxrwx 3 root root 4.0K Jan 2 12:56 .
drwxr-xr-x 1 root root 4.0K Jan 2 12:56 ..
drwxr-xr-x 2 root root 4.0K Jan 2 12:56 ..2022_01_02_12_56_24.426266088
lrwxrwxrwx 1 root root 31 Jan 2 12:56 ..data -> ..2022_01_02_12_56_24.426266088
lrwxrwxrwx 1 root root 22 Jan 2 12:56 game.properties -> ..data/game.properties
lrwxrwxrwx 1 root root 20 Jan 2 12:56 ui.properties -> ..data/ui.properties
选择指定的键,对其重命名后,挂载到容器内
spec:
containers:
- volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: app-config
items:
- key: game.properties
path: game
验证容器内挂载情况
➜ kubectl exec -it hello-world -- ls -lha /etc/config
total 12
drwxrwxrwx 3 root root 4.0K Jan 2 13:32 .
drwxr-xr-x 1 root root 4.0K Jan 2 13:32 ..
drwxr-xr-x 2 root root 4.0K Jan 2 13:32 ..2022_01_02_13_32_04.212421978
lrwxrwxrwx 1 root root 31 Jan 2 13:32 ..data -> ..2022_01_02_13_32_04.212421978
lrwxrwxrwx 1 root root 11 Jan 2 13:32 game -> ..data/game
2) Secret 映射到卷#
Secret 在使用上和 ConfigMap 没什么不同。
创建一个 Secret
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: consume-secret-in-volume-secret
type: Opaque
data:
username: TFEK
password: MTIzNDU2Cg==
EOF
将整个 Secret 映射成卷,所有的键映射成文件,挂载到容器内
spec:
containers:
- volumeMounts:
- name: foobar
mountPath: /etc/config
readOnly: true
volumes:
- name: foobar
secret:
secretName: consume-secret-in-volume-secret
验证容器内挂载情况
➜ kubectl exec -it hello-world -- ls -lha /etc/config
total 4.0K
drwxrwxrwt 3 root root 120 Jan 2 15:39 .
drwxr-xr-x 1 root root 4.0K Jan 2 15:40 ..
drwxr-xr-x 2 root root 80 Jan 2 15:39 ..2022_01_02_15_39_55.479935230
lrwxrwxrwx 1 root root 31 Jan 2 15:39 ..data -> ..2022_01_02_15_39_55.479935230
lrwxrwxrwx 1 root root 15 Jan 2 15:39 password -> ..data/password
lrwxrwxrwx 1 root root 15 Jan 2 15:39 username -> ..data/username
我们来看下 password 的内容
➜ kubectl exec -it hello-world -- cat /etc/config/password
123456
通过修改 Secret 后
➜ kubectl patch secret consume-secret-in-volume-secret -p '{"data":{"password":"YWJjMTIzNAo="}}'
secret/consume-secret-in-volume-secret patched
再次查看 password 内容,发现内容有了变化
➜ kubectl exec -it hello-world -- cat /etc/config/password
abc1234
通过以上的实验,我们只要更新 Secret,挂载到 Secret 卷的文件内容也会更新,如果你的应用程序支持热加载的话,那么应用会立即生效。
⚠️ 小结以及一些注意项
ConfigMap/Secret 不是用来存大数据的,每一个资源的数据不可超过 1 MB,这其实是受到它的底层存储 Etcd 的限制。
对于 Pod 内如何使用 ConfigMap,官方文档给出了详细的说明
#3. 容器镜像#
不难发现,不管我们是采用 环境变量 还是 配置文件 哪一种方式和代码做配置上的解耦,这两种资源的数据都是会被更改的。
有些使用场景下,应用需要保证输入配置的不可变性,我们可以利用 Kubernetes 容器设计模式之初始化容器 和容器镜像的不可变性,来实现这点。
我在以前的文章中分享过这块的使用案例,这里就不在做重复叙述了,可以点击下图直接跳转查看。
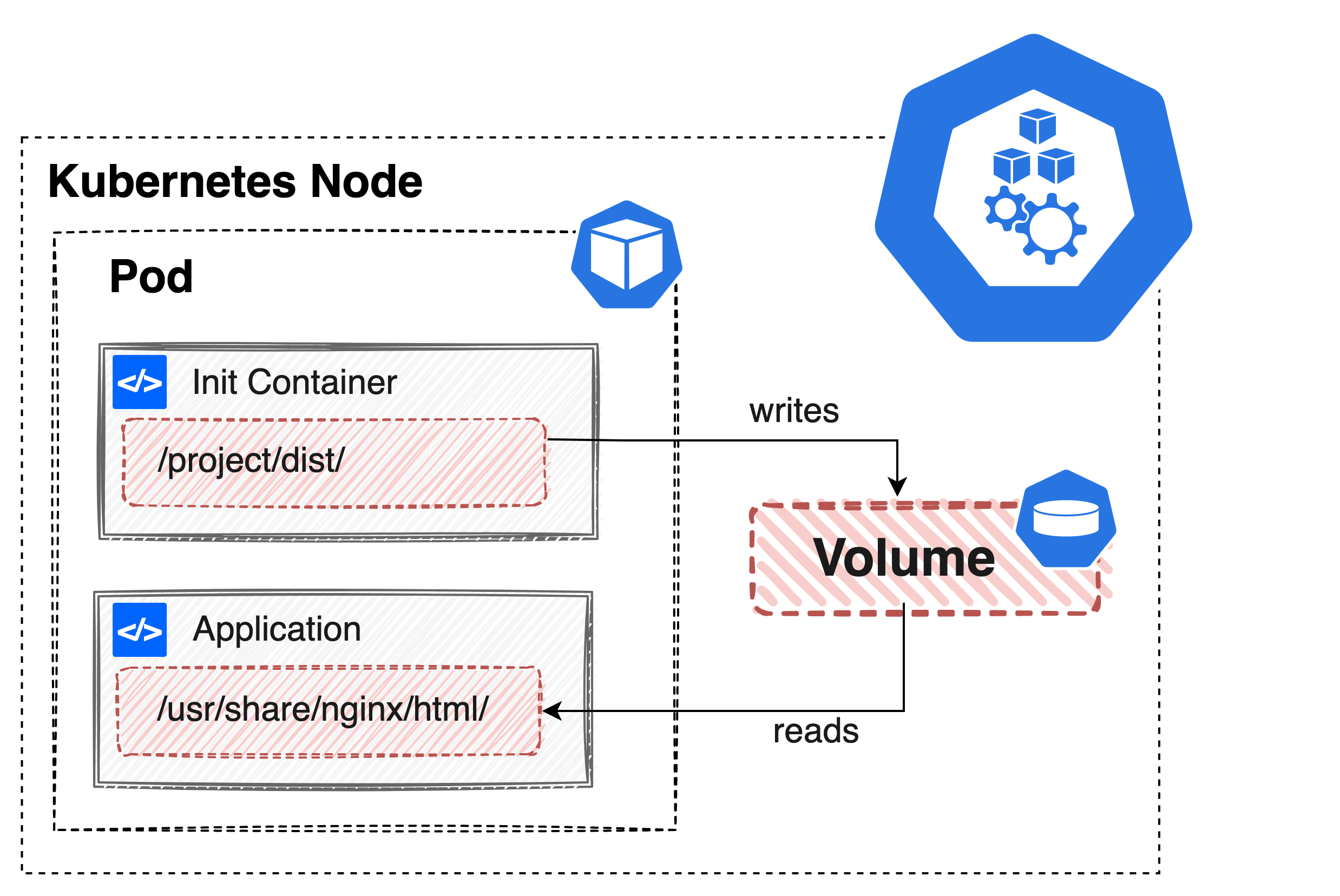
小结以及一些注意项
- 这种方式虽然增加了配置镜像打包的环节,但是配置和主应用一样有版本的概念,好处大于坏处
- 另外上面也提到过因为受 Etcd 的限制,ConfigMap 和 Secret 这两种资源不能存放太大的数据,使用容器镜像就不受这一限制
#4. 结论#
以上介绍了三种在 Kubernetes 世界里配置和代码解耦的方法,每一种方案没有绝对的好坏之分。
所以如果抛开使用场景来评价好坏,那都是耍流氓,希望大家找到适合自己应用的最佳解决方案。
② 日志输出#
每个应用程序都会有它的日志输出,有的同学会根据自己平时的习惯,特别喜欢将应用日志输入到一个特定目录的文件下,方便自己来排查问题。但是,对于一个容器应用来说,不建议将日志写入到指定的文件中。
我们应该将应用的日志输出到 stdout 和 stderr,在默认情况下这些日志会被输出到宿主机上的一个 JSON 文件里。
比方说 Container Runtime 如果是 docker 的话,应用程序的日志会默认保存在宿主机的 /var/lib/docker/containers/{{. 容器 ID}}/{{. 容器 ID}}-json.log 文件里。
为什么需要这样做呢?这里有几点原因
- 方便运维人员的排查,我们平时常用的 kubectl logs 命令看到的日志就来源于此。如果你的应用日志写到了某个文件里。如果出了问题,你让他怎么查?还要先找到应用文档,找到日志目录,很浪费时间。
- 日志应该是事件流的汇总,这样在多副本情况下,会保证日志的连续性
- 方便 logging agent 集中处理日志
这也是
The Twelve-Factor App推荐的方式,将日志当作事件流来处理。
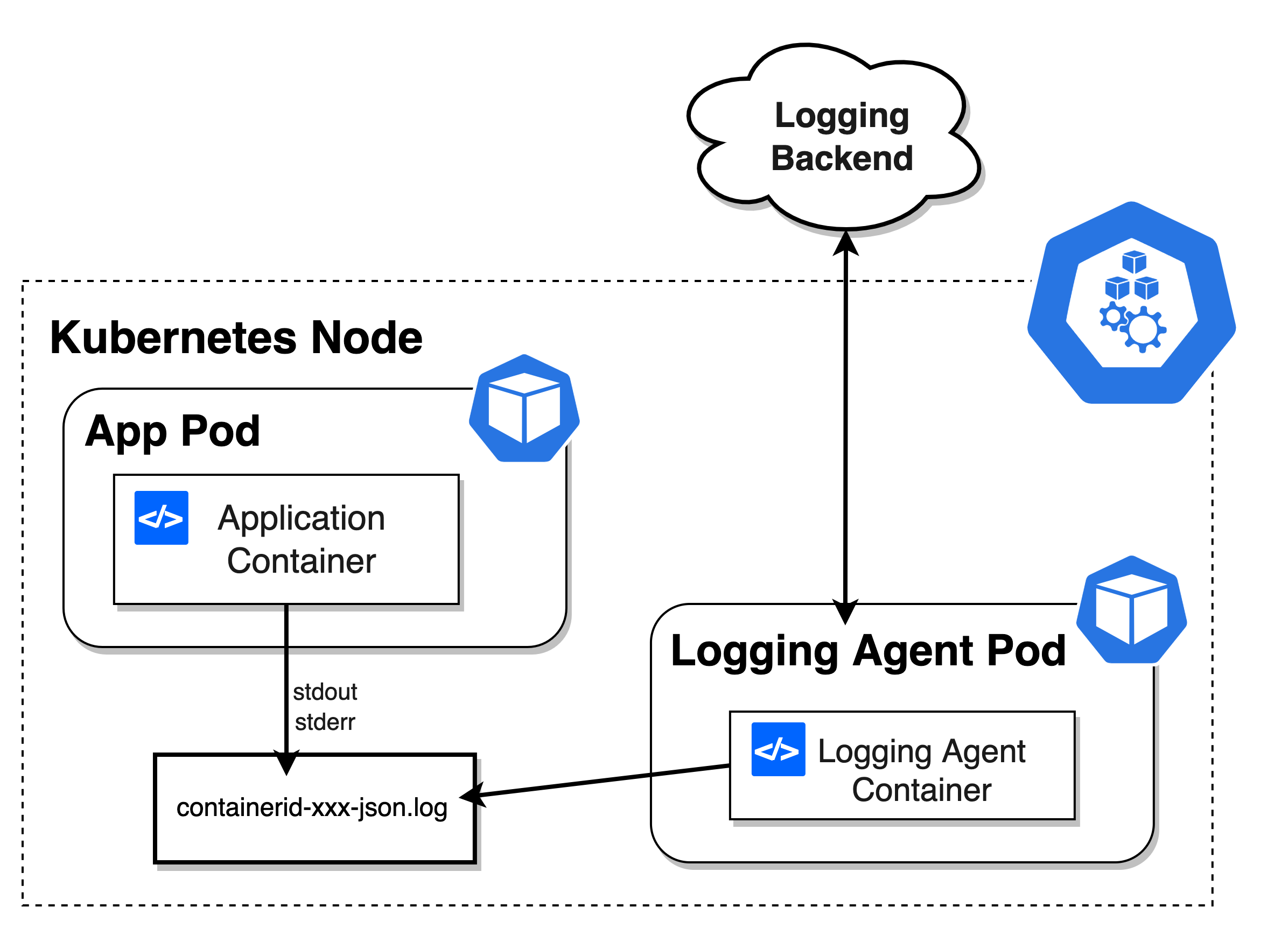
③ 网络访问相关#
#1. 集群内的 IP,集群外不能访问#
让我们先创建一个 Pod,将脚本放在 Kubernetes 集群内执行
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: hostname
labels:
app: hostname
spec:
containers:
- name: hostname
image: k8s.gcr.io/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
EOF
从以下信息可以看到,刚刚这个 Pod 在集群内的有了一个 IP
➜ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hostname 1/1 Running 0 98s 10.244.0.21 local-k8s-control-plane <none> <none>
首先需要声明的是 10.244.0.21 这个IP在集群外是访问不到的
➜ telnet 10.244.0.21 9376
Trying 10.244.0.21...
telnet: connect to address 10.244.0.21: Operation timed out
telnet: Unable to connect to remote host
访问不到,那我调试怎么办?别急,我们可以通过端口转发来绕过这个问题。
kubectl port-forward 将 localhost:9376 的请求转发到 Pod 的 9376 端口
➜ kubectl port-forward hostname 9376
Forwarding from 127.0.0.1:9376 -> 9376
Forwarding from [::1]:9376 -> 9376
将集群上的端口转发到本地后,本地就可以通过 localhost 来访问了,以下是简单验证
➜ telnet localhost 9376
Trying ::1...
Connected to localhost.
Escape character is '^]'.
➜ curl localhost:9376
hostname
#2. 集群内访问走 Service#
如果我的服务都在集群内,我能不能直接通过 Pod IP 来直接访问呢?
当然可以.
➜ kubectl run ephemeral-busybox \
--rm \
--stdin \
--tty \
--restart=Never \
--image=lqshow/busybox-curl:1.28 \
sh
/data # curl 10.244.0.21:9376
hostname
但是一般我们都不建议直接通过访问 Pod IP 的方式去访问另外一个服务,为什么呢?主要有以下两个原因
- Pod 的 IP 不是固定的,而且 Pod 是很脆弱的,当 Pod 发生故障后,一但被调度到其他节点或者重启后,会生成一个新 IP 地址
- 同一个应用多实例情况,每个副本实例都会对应一个 Pod,每个 Pod 都有它自己的一个 IP
那么怎么解决这个问题呢? Kubernetes 提供了 Service 这个资源抽象,它实现了对一组 Pod 的访问方式的抽象,主要通过 Label 来寻找对应的 Pod,同时提供服务发现和流量负载均衡的能力。
所以,对开发者来说,你完全不需要记住 Pod 的 IP 地址,只需关心你需要访问服务的 service name 即可。
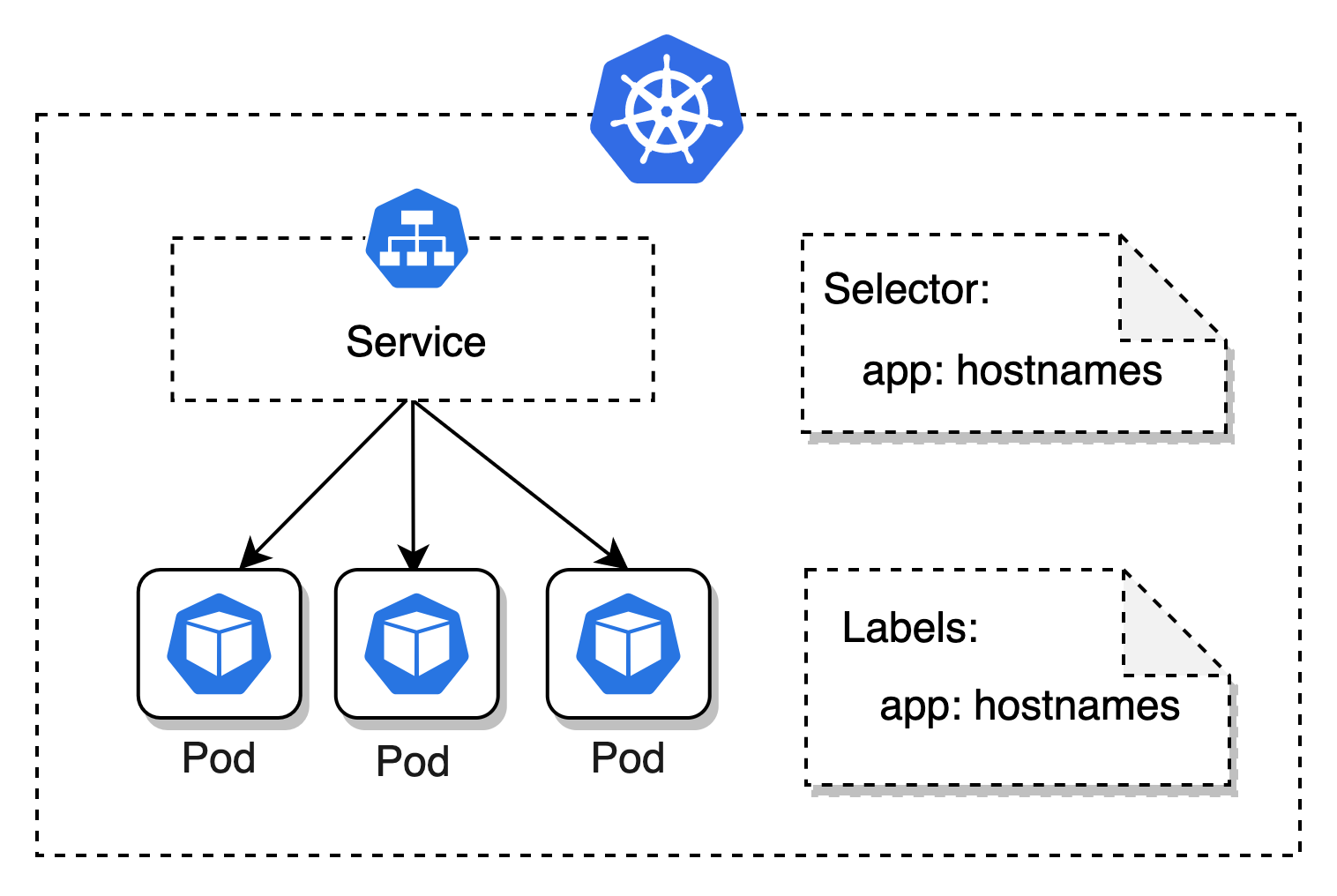
先创建一个 Service 资源,通过 selector 字段来筛选 app=hostnames 的 Pod
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80
targetPort: 9376
EOF
然后通过 Deployment 创建多副本实例
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: k8s.gcr.io/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
EOF
查看集群内生成的 Pod 情况
➜ kubectl get pod -owide -l app=hostnames
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hostnames-5f9c957df4-br4k2 1/1 Running 0 18s 10.244.0.25 local-k8s-control-plane <none> <none>
hostnames-5f9c957df4-mjfdm 1/1 Running 0 18s 10.244.0.26 local-k8s-control-plane <none> <none>
hostnames-5f9c957df4-smck7 1/1 Running 0 18s 10.244.0.24 local-k8s-control-plane <none> <none>
可以查看这个 Serivce 的 endpoints 信息。
⚠️ 这里说明一下,如果你的 Pod 是 Running 的,但是 Service 不能正常提供服务,一定要先确认下,这个 Service 的 endpoints 列表里有没这个 Pod 的 IP。
➜ kubectl get ep hostnames
NAME ENDPOINTS AGE
hostnames 10.244.0.24:9376,10.244.0.25:9376,10.244.0.26:9376 3m3s
验证直接通过 service name 去访问的效果
➜ kubectl run ephemeral-busybox \
--rm \
--stdin \
--tty \
--restart=Never \
--image=lqshow/busybox-curl:1.28 \
-- sh
/data # curl hostnames
hostnames-5f9c957df4-mjfdm
/data #
/data # curl hostnames
hostnames-5f9c957df4-br4k2
/data #
/data # curl hostnames
hostnames-5f9c957df4-mjfdm
#3. 结论#
- 一个 Pod 一个 IP,Pod 内容器之间的通信,直接通过 localhost 访问。
- 集群内访问走 Service
- <自定义的访问方式名称>.<工作负载所在命名空间> (例如:redis-svc.default)
- <自定义的访问方式名称>.<工作负载所在命名空间>.svc.cluster.local(例如:redis-svc.default.svc.cluster.local)
对于 Service 的一些 Debug 流程,可以参考官网的详细说明
Role of an App Operator#
① 数据持久化#
我们知道 Pod 是比较容易被销毁的,销毁后 Pod 内的 Container 是以最初始的状态被重新拉起。
所以如果你应用里的数据需要做持久化的话,是不能直接写在 Container 的文件系统内的。
当然,在某些情况下,如果只是为了给 Pod 提供一个在多 Container 之间的数据共享,还是可以用下 emptyDir 的,不过它的生命周期同 Pod 一致。
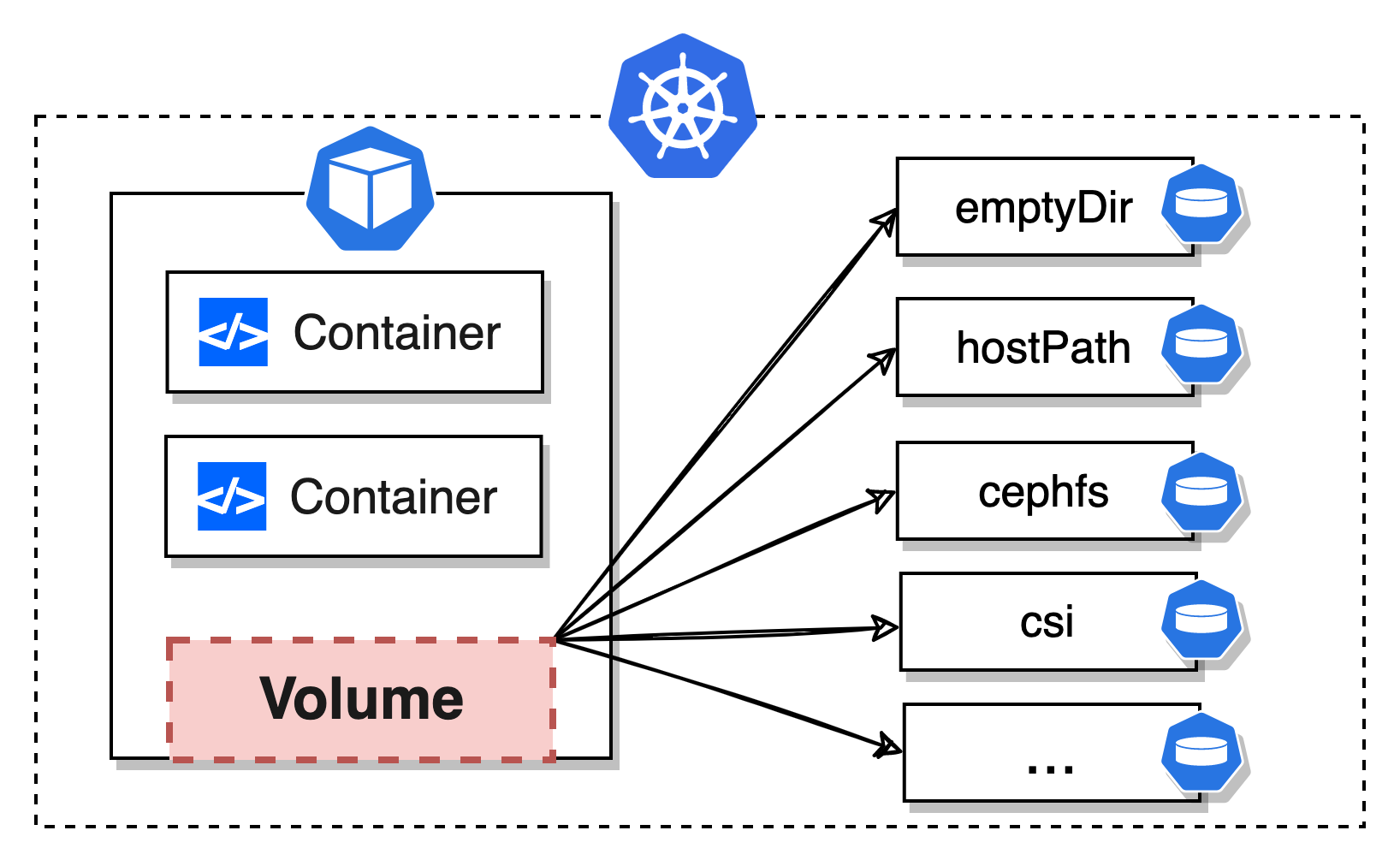
Kubernetes 抽象出了各种 Volume 类型,开发者可以根据自己项目的实际情况,按需选择即可。具体可以参考官方提供的两个文档,都做了很详细的介绍
② 控制器管理#
举个简单例子,比方说将 Nginx 服务部署到 Kubernetes 集群,只需通过 Deployment 资源来部署一个无状态应用即可
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
# 副本控制
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21.5
ports:
- containerPort: 80
# 健康检查
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
# 资源管理
resources:
limits:
memory: 50Mi
cpu: 100m
requests:
memory: 10Mi
cpu: 10m
EOF
执行以上脚本,会在集群内拉起 2个 Nginx 实例
➜ kubectl get pod -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-557954c8b6-2qxww 1/1 Running 0 32m 10.244.0.14 local-k8s-control-plane <none> <none>
nginx-557954c8b6-zr7vj 1/1 Running 0 32m 10.244.0.15 local-k8s-control-plane <none> <none>
类似 Deployment 这种控制编排器,Kubernetes 提供了很多,大家完全可以自行查看 Kubernetes 项目去做下了解
③ 集群外访问走 Ingress#
应用已经部署在 Kubernetes 中了,那么我们在集群外通过什么方式来访问呢?
文中在网络访问相关模块其实有提到过 Service 这个资源,我们其实可以通过 Service 来直接将应用暴露到外网。
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
spec:
ports:
- port: 3000
targetPort: 80
protocol: TCP
nodePort: 32143
type: NodePort
selector:
app: nginx
EOF
我们来看下 Service 的信息
➜ kubectl get svc nginx-svc -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx-svc NodePort 10.96.0.40 <none> 3000:32143/TCP 56s app=nginx
这里有必要对 Service 的端口做下说明,port 和 nodePort 都是 Service 上的端口
| Port | Desc |
|---|---|
| port | Service 暴露在 cluster ip 上的端口(3000),主要提供集群内服务访问的 |
| targetPort | 指向Pod 里容器的端口(80) |
| nodePort | Node 里的端口(32143),主要是暴露给集群外访问的 |
root@local-k8s-control-plane:/# curl localhost:32143
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
虽然我们在节点上确实能通过 32143 访问成功,但是相信大家也注意到了,如果用这种方式的话,我们要给每一个 Service 都配置一个节点上的端口,在调试阶段用用还可以。
对外部署显然是不可能的,因为客户也不会预留这么多端口给到我们。
这里就不得不提 Ingress 这个资源了,它其实类似 Nginx 负载均衡的代理服务器,它为 Kubernetes 提供了集群外部的访问入口,可以将外部流量转发到集群内不同的 Service。
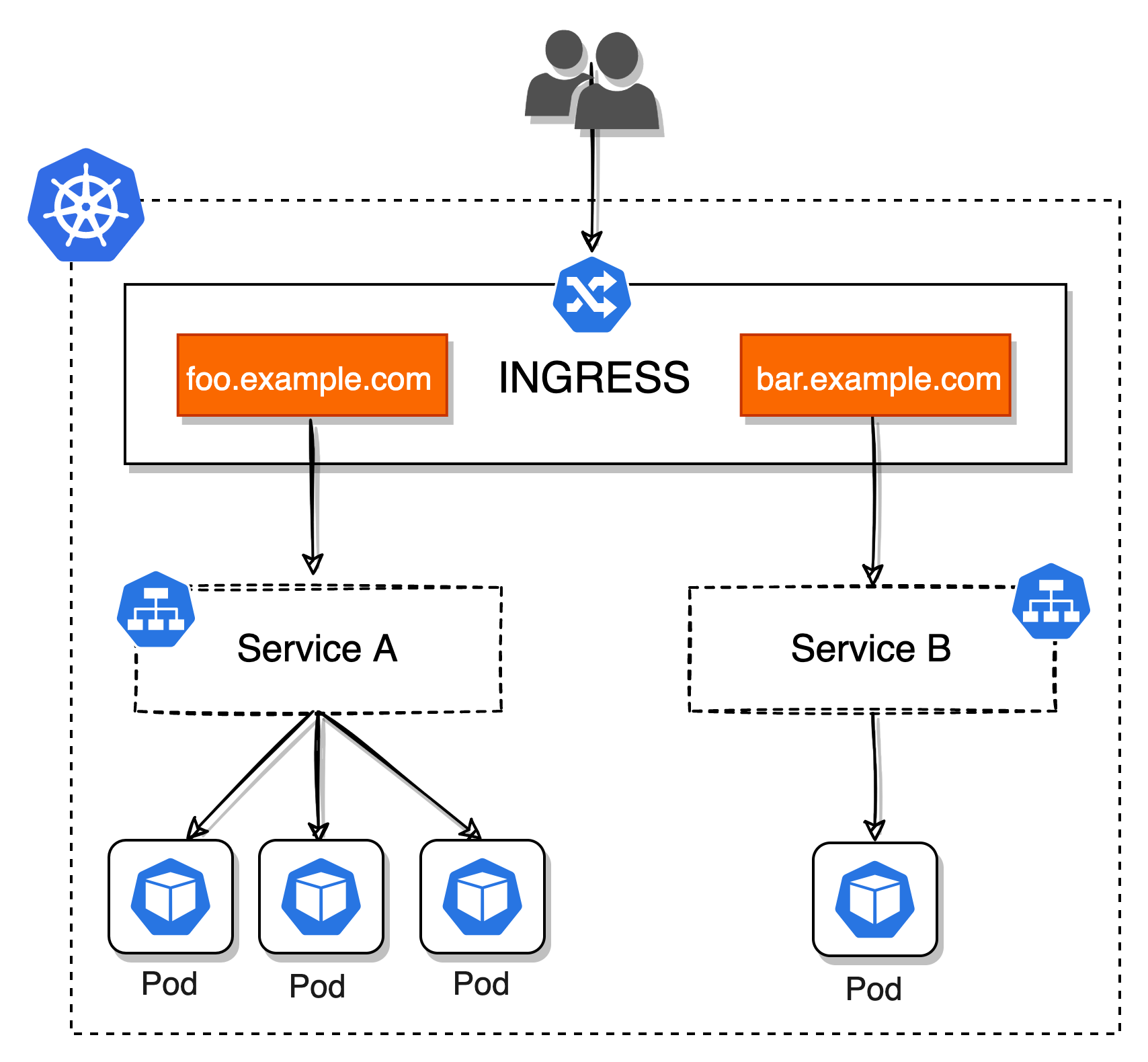
但是前提集群内必须要有 Ingress Controller 来支撑,比如说 traefik-ingress 或者 nginx-ingress-controller 都行。
写在最后#
其实对于应用开发者来说,在开发过程中需要关注应用上 Kubernetes 的知识点并不多。
不论是配置与代码解耦,还是将日志当做事件流,我相信应用在 Docker 容器里跑的时候,这两点大家早就已经这么做了对吧?
唯一需要关注的点是在 Kubernetes 集群内不同应用之间的访问方式,以及在 Kubernetes 中是如何将配置集成到应用里的。
大家肯定也注意到了,以上一个无状态应用我们至少提到了 ConfigMap、Secret、Service、Deployment 以及 Ingress 这么多细粒度的资源。
我们最后将应用交付给运维工程师去部署的时候,难道也是这样吗?当然不是,不然这次运维工程师要开始崩溃了。。。
下一期我会继续给大家分享怎么将这些资源打包,解决应用如何交付的问题。
